Meta descrição: Aprenda como configurar n8n em alta disponibilidade na VPS com workers, Redis e banco gerenciado. Guia prático de arquitetura.
Manter automações rodando 24/7 é o tipo de coisa que só chama atenção quando dá problema. Um fluxo que falha no meio de uma pico de vendas, um webhook que fica fora do ar durante uma lançamento, ou um agente de IA que para de responder porque o servidor “travou” — tudo isso custa tempo, dinheiro e confiança.
Quando você pesquisa como configurar n8n em alta disponibilidade na VPS, normalmente está tentando sair do cenário mais simples (um único container/instância) e entrar em uma arquitetura que aguenta:
- mais execuções simultâneas;
- tarefas pesadas (scraping, IA, manipulação de arquivos, integrações grandes);
- quedas pontuais sem parar o mundo;
- manutenção planejada com menos impacto.
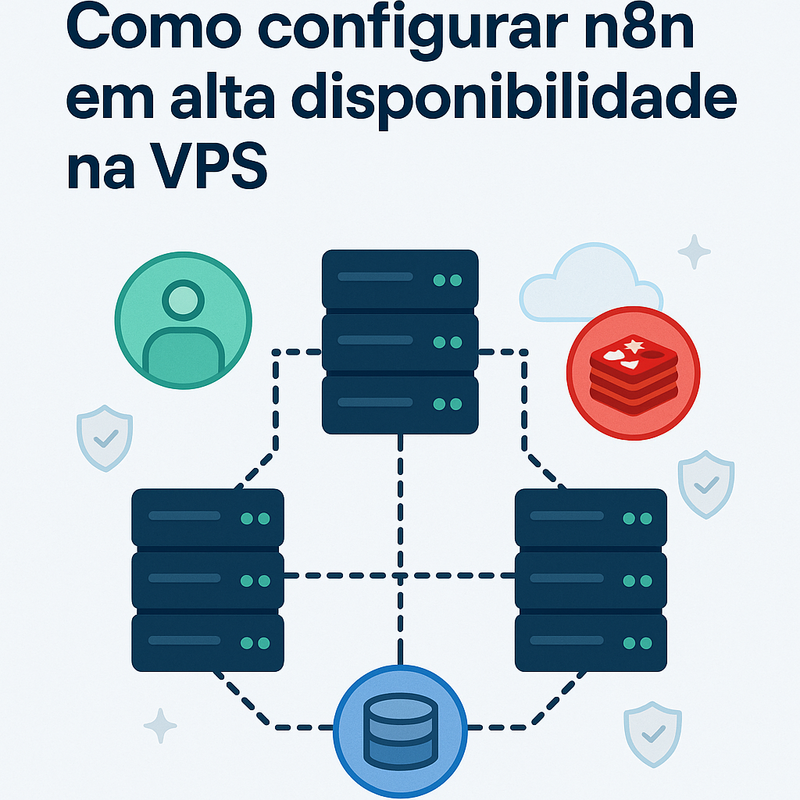
A ideia central é desacoplar responsabilidades. Em vez de uma única instância do n8n fazendo “tudo”, você separa:
- uma instância “principal” (main) para interface, webhooks e orquestração;
- workers para processar execuções em paralelo;
- Redis para fila (queue) e coordenação de jobs;
- PostgreSQL gerenciado (ou ao menos fora do container) para persistência confiável.
Isso não transforma uma única VPS em um “cluster mágico”, mas dá um salto enorme de robustez e escalabilidade sem complicar demais. É o tipo de setup que já atende bem muitos projetos reais: agências, automações internas, atendimento via WhatsApp/Telegram, integrações com CRMs e pipelines com IA.
Ao longo deste guia, você vai entender o que muda ao usar n8n queue mode com Redis, como pensar em workers do n8n em VPS, como encaixar um PostgreSQL gerenciado para n8n e quais boas práticas realmente ajudam quando o objetivo é alta disponibilidade (com o mínimo de dor).

Por que buscar alta disponibilidade no n8n?
Alta disponibilidade (HA) é um termo que parece “coisa de empresa grande”, mas na prática ele começa a fazer sentido bem cedo — especialmente quando o n8n vira uma peça central do seu negócio.
No modo mais comum (uma instância única), o n8n costuma rodar junto com o banco e às vezes até com Redis no mesmo lugar. Isso funciona para aprender e para projetos pequenos, mas tem limitações claras:
- Ponto único de falha: se o processo do n8n parar (crash, update malfeito, falta de memória), tudo para: webhooks, execuções agendadas e processamentos.
- Concorrência limitada: muitos fluxos ao mesmo tempo podem disputar CPU/RAM e deixar a UI lenta. O problema não é “n8n ser ruim”, é o desenho do ambiente.
- Tarefas longas travam o resto: um workflow pesado pode atrasar outros — e isso aparece como “instabilidade” para quem está consumindo seus webhooks.
- Manutenção vira risco: atualizar versão, reiniciar containers e ajustar configurações vira um mini-evento, porque não existe folga.
Quando você começa a pensar em como configurar n8n em alta disponibilidade na VPS, o objetivo geralmente é reduzir esses impactos e ganhar previsibilidade.
O que HA significa (na vida real) para quem usa n8n
Para iniciante, vale simplificar: HA não é “nunca cair”; é “quando cair, o impacto é menor e a recuperação é rápida”. Em n8n, isso normalmente envolve:
- separar processamento do atendimento: webhooks/UI ficam em uma instância mais “leve”, enquanto workers fazem o trabalho pesado;
- fila para absorver picos: quando chegam muitos eventos, eles entram na fila (Redis) e são processados conforme capacidade;
- banco confiável e fora do container: o estado do n8n (credenciais, execuções, configurações) precisa estar seguro.
Exemplos práticos de problemas que HA evita
Imagine três cenários comuns:
- Um webhook do seu e-commerce recebe 300 pedidos em 10 minutos. Sem fila, pode saturar a instância; com fila e workers, você processa com controle.
- Um workflow chama uma IA, espera resposta, faz parsing e grava em várias ferramentas. Com workers, isso não “prende” a interface e os webhooks.
- Você precisa atualizar o n8n. Com arquitetura mais bem separada, você reduz o risco de perder execuções e consegue voltar mais rápido.
No fim, buscar alta disponibilidade é mais sobre confiabilidade operacional do que sobre “tecnologia sofisticada”. E dá para chegar bem longe dentro de uma VPS, desde que você organize o ambiente com fila, workers e banco bem definido.
🤖 Um próximo passo natural: aprender a criar agentes e automações “de verdade” no n8n
Quando você começa a se preocupar com alta disponibilidade, normalmente é sinal de que o n8n já está virando parte importante do seu trabalho (ou do seu produto). E aí faz sentido também evoluir do “rodar um fluxo” para projetar automações e agentes de IA com padrão profissional: reaproveitamento, monitoramento, boas práticas de integração e arquitetura.
Uma indicação bem honesta, se você quer encurtar caminho, é a Formação Agentes de IA (n8n) da Hora de Codar. Ela é bem pé no chão para iniciantes, mas vai fundo no que importa: do básico do n8n até agentes com IA, integrações, projetos completos e configuração mais profissional.
Eu gosto porque o foco é mão na massa, com bastante conteúdo (são 11+ cursos, 221+ aulas, 20h+ e 21+ projetos) e uma trilha que te ajuda a construir portfólio.
Se quiser dar uma olhada na grade e ver se faz sentido para o seu momento: https://app.horadecodar.com.br/lp/formacao-agentes-de-ia-n8n?utm_source=blog

Entendendo o queue mode com Redis no n8n
O n8n queue mode com Redis é um dos pilares para escalar e deixar o ambiente mais resiliente. A ideia é simples: em vez do n8n executar o workflow imediatamente no mesmo processo que recebeu o evento, ele coloca a execução em uma fila. Aí, um ou mais workers vão “puxando” os jobs dessa fila e processando.
Por que Redis entra nessa história?
O Redis funciona como um “correio rápido” entre a instância principal e os workers. Ele guarda e distribui as mensagens da fila, garantindo que:
- execuções sejam enfileiradas com baixa latência;
- múltiplos workers possam consumir em paralelo;
- você consiga absorver picos de demanda sem derrubar webhooks/UI.
Pense assim: o Redis não substitui o banco (PostgreSQL). Ele é a camada de coordenação e fila. O banco continua sendo o lugar onde o n8n persiste o que precisa (execuções, credenciais, etc.).
O que muda no comportamento do n8n
No modo “simples”, a mesma instância que recebe o webhook normalmente executa o workflow. No queue mode, você tende a ter papéis diferentes:
- Main (ou “primary”): recebe webhooks, mostra a UI, agenda execuções e envia jobs para a fila.
- Workers: processam jobs da fila e registram resultados no banco.
Isso já melhora bastante a estabilidade, porque seu “front” (UI e webhooks) fica menos exposto a travamentos por carga.
Quando o queue mode vale a pena
Você costuma sentir vantagem quando:
- há muitos webhooks chegando em curtos períodos;
- você quer rodar várias execuções simultâneas;
- os workflows são pesados (IA, PDFs, integrações longas);
- você quer aumentar capacidade “adicionando workers”, em vez de aumentar uma única instância.
Cuidados importantes (para não se frustrar)
Queue mode não é “ligar e esquecer”. Alguns pontos básicos evitam dor:
- Redis precisa estar estável: se Redis cair, fila para. Em HA, você monitora e protege o Redis.
- Workers precisam acessar o mesmo banco: main e workers devem estar apontando para o mesmo PostgreSQL.
- Atenção a recursos da VPS: colocar 10 workers em uma VPS pequena vai piorar, não melhorar. Escalar é equilibrar CPU/RAM.
Na prática, Redis + queue mode é a forma mais “natural” de escalar n8n mantendo o desenho simples. E é exatamente o tipo de arquitetura que aproxima você de um cenário de alta disponibilidade mesmo sem montar um cluster completo.
Vídeo recomendado: como instalar n8n na VPS (base perfeita antes de escalar para HA)
Antes de partir para queue mode, Redis e workers, faz muita diferença ter uma instalação base do n8n bem feita na VPS (com domínio/SSL e tudo organizado). Este vídeo é um ótimo ponto de partida para você montar o “alicerce” e depois evoluir para uma arquitetura de alta disponibilidade.
Assista aqui e siga o passo a passo:
Link direto: https://www.youtube.com/embed/VCKzXFk_XjM?si=eOBTMrjZNPj3q07Z
Configurando workers do n8n em uma VPS
Quando falamos em workers do n8n em VPS, estamos falando de separar o “cérebro” que recebe e organiza (main) dos “braços” que executam (workers). Isso dá um ganho enorme para quem quer rodar automações em produção, porque você pode aumentar ou reduzir capacidade sem mexer no ponto que atende webhooks e interface.
Modelo mental: main vs workers
Em uma arquitetura típica na VPS:
- a instância main expõe a interface web, gerencia credenciais, agenda execuções e enfileira jobs no Redis;
- as instâncias worker ficam consumindo a fila e executando as etapas do workflow.
O segredo é: main e workers apontam para o mesmo Redis e o mesmo PostgreSQL. Assim, o estado do sistema é compartilhado.
Como organizar isso na prática (sem complicar)
O jeito mais comum é usar Docker (ou Docker Compose) e subir serviços separados:
n8n-mainn8n-worker(pode ter mais de um)redis- (opcional)
traefik/nginxpara proxy reverso
Em termos de configuração, você habilita o modo fila e aponta as credenciais do Redis e do banco para todos. A principal diferença dos workers é que eles rodam com um “perfil” de worker (ou variáveis específicas) para não tentar assumir as mesmas responsabilidades da instância principal.
Quantos workers devo criar?
Aqui é onde muita gente erra por excesso. O ideal é começar pequeno:
- 1 main + 1 worker já faz diferença.
- Se a VPS tiver folga (CPU/RAM), adicione mais 1 worker e observe.
O número certo depende do peso dos fluxos. Workflows com IA e chamadas externas longas podem se beneficiar de mais workers, mas também podem consumir muita memória.
Dicas de estabilidade em VPS
Algumas decisões simples melhoram bastante a operação:
- Limite de recursos por container/processo: evita que um workflow pesado “mate” o servidor.
- Logs e reinício automático: configure restart policy para serviços essenciais.
- Separação de rede interna: mantenha Redis e banco sem exposição pública.
E um detalhe importante: alta disponibilidade não é só “mais workers”. Workers ajudam na capacidade e na resiliência a carga, mas você ainda precisa de um bom banco e de boa camada de rede para o acesso.
Onde entra o proxy reverso
Mesmo em uma VPS só, usar Nginx/Traefik com HTTPS ajuda a padronizar:
- certificado TLS;
- roteamento para a instância main;
- headers corretos para webhooks.
Os workers não precisam ficar expostos. Quem precisa receber tráfego externo geralmente é só o main (e o proxy reverso na frente).
Com isso, você transforma o n8n de “um app único” em um ambiente mais parecido com produção: main leve, workers escaláveis e serviços de suporte isolados. É um passo essencial dentro do caminho de como configurar n8n em alta disponibilidade na VPS.
Integrando PostgreSQL gerenciado ao ambiente n8n
Se tem um componente que você não quer “brincar” quando o assunto é produção, é o banco. O n8n guarda no banco coisas críticas: credenciais (criptografadas), configurações, histórico de execuções, filas internas e metadados de workflows. Por isso, usar PostgreSQL gerenciado para n8n costuma ser uma das decisões mais certeiras para aumentar confiabilidade.
Por que banco gerenciado ajuda na alta disponibilidade
Em uma VPS, você pode até rodar Postgres em container, mas isso traz responsabilidades extras:
- backup consistente;
- atualizações e patches;
- tuning e performance;
- risco de corromper volume em queda abrupta;
- monitoramento e alertas.
Com um Postgres gerenciado, essas tarefas normalmente ficam muito mais simples (e, em muitos provedores, parcialmente automatizadas). Você reduz o “trabalho invisível” que aparece só quando dá ruim.
O que muda na arquitetura do n8n
Quando você tira o Postgres da VPS e coloca em um serviço gerenciado:
- a VPS fica mais livre (CPU/RAM/IO) para o n8n e workers;
- a persistência crítica fica em um componente mais robusto;
- sua recuperação em caso de problemas no servidor fica mais rápida (basta subir de novo o n8n e apontar para o mesmo banco).
Na prática, isso é um ganho direto para o objetivo de como configurar n8n em alta disponibilidade na VPS: você separa estado (banco) de compute (VPS).
Cuidados para não perder performance e segurança
Alguns pontos simples evitam armadilhas:
- Latência: escolha um Postgres gerenciado na mesma região do seu VPS.
- TLS/SSL: prefira conexão segura ao banco (muitos serviços exigem).
- Firewall/rede: libere acesso ao banco apenas para o IP da sua VPS.
- Conexões: muitos workers abrem mais conexões. Se necessário, ajuste limites (ou use pooler como PgBouncer, dependendo do caso).
Migrando com calma (sem downtime grande)
Se você já tem um n8n rodando com Postgres local, a migração costuma seguir este roteiro:
1) Faça backup do banco atual.
2) Suba/restaure no Postgres gerenciado.
3) Aponte as variáveis de ambiente do n8n (main e workers) para o novo host.
4) Teste login, workflows e execuções.
O segredo é testar em horário de baixa e validar fluxos críticos primeiro (webhooks, filas, credenciais).
Resultado esperado
Quando o Postgres está bem configurado e fora da VPS, você percebe:
- menos travamentos em picos;
- reinícios mais rápidos;
- manutenção mais tranquila;
- base mais sólida para crescer o número de workers.
Ou seja: workers e Redis fazem o n8n aguentar volume; o Postgres gerenciado garante que seu “histórico e cérebro” permaneçam seguros e consistentes.
💻 VPS para n8n com boa estabilidade: por que eu consideraria a Hostinger
Mesmo com Redis, workers e banco gerenciado, a sua VPS ainda é o “motor” do ambiente (onde rodam o main, workers, proxy reverso etc.). Então escolher uma VPS estável e fácil de gerenciar ajuda muito, principalmente para quem está começando.
A VPS da Hostinger é uma opção bem prática para projetos com n8n porque você consegue subir o ambiente rápido, tem escalabilidade quando precisar e ainda conta com infraestrutura voltada para manter os fluxos rodando com consistência (eles falam em 99,9% de uptime). Outro ponto legal é ter planos com NVMe (que ajuda bastante em IO) e a possibilidade de crescer CPU/RAM sem precisar “migrar tudo do zero”.
Se você quiser ver os planos por lá, usando o link de indicação, aqui está:
https://www.hostinger.com.br/horadecodar
E para economizar, use o cupom: HORADECODAR
Dica rápida: se você já sabe que vai usar queue mode + workers, eu começaria pelo menos com um plano na faixa de 8 GB de RAM (e subir conforme o volume), porque automações com IA e múltiplas execuções simultâneas tendem a consumir memória.

Boas práticas e recomendações para alta disponibilidade
Depois de montar a arquitetura com main, workers do n8n em VPS, n8n queue mode com Redis e PostgreSQL gerenciado para n8n, o que realmente mantém o ambiente saudável são as práticas do dia a dia. Alta disponibilidade não é só desenho — é operação.
1) Planeje o que acontece quando algo falha
Perguntas simples ajudam muito:
- Se o Redis cair, como você fica sabendo?
- Se o worker travar, ele reinicia sozinho?
- Se a VPS reiniciar, o n8n volta automaticamente?
Ter reinício automático e monitoramento básico já evita “madrugadas de susto”.
2) Use limites e evite o “efeito dominó”
Um workflow pesado não pode derrubar tudo. Algumas estratégias comuns:
- limitar memória/CPU por container;
- reduzir concorrência (melhor processar um pouco mais lento do que ficar instável);
- dividir workflows muito grandes em etapas menores.
3) Cuide dos webhooks e do tempo de resposta
Mesmo com fila, webhooks precisam responder rápido para quem chamou. Uma prática comum é:
- responder “200 OK” rápido e processar o resto em background (quando o seu caso permitir);
- evitar passos longos logo no começo do workflow de webhook.
4) Backups e retenção de execuções
O banco é crítico, mas o volume de execuções cresce. Vale revisar:
- política de retenção de execuções no n8n (para não inflar o banco);
- backups automáticos no Postgres gerenciado;
- export de workflows importantes (versionamento ajuda muito).
5) Observabilidade: logs, métricas e alertas
Sem exagero: só o básico bem feito já resolve para iniciantes.
- centralize logs (nem que seja com o próprio Docker +
journalctl+ um viewer); - configure alertas de uso de CPU/RAM/Disco;
- acompanhe filas crescendo (sinal de worker insuficiente ou workflow travado).
6) Atualizações com cuidado
Atualizar n8n em produção é normal, mas faça com método:
- leia changelog;
- faça snapshot/backup antes;
- atualize primeiro em ambiente de teste se possível;
- suba versão nova e monitore execuções.
Em resumo
Se você aplicar essas práticas, sua arquitetura deixa de ser “apenas um setup com Redis e workers” e vira um ambiente realmente confiável. E o melhor: é um caminho incremental. Você pode começar com 1 worker e ir evoluindo conforme a demanda, sempre mantendo o foco no objetivo: como configurar n8n em alta disponibilidade na VPS com o máximo de estabilidade e o mínimo de complexidade.
O que é necessário para configurar o n8n em alta disponibilidade na VPS?
Para configurar o n8n em alta disponibilidade na VPS, você precisa estruturar sua arquitetura utilizando múltiplos workers para processar tarefas em paralelo, um serviço Redis para orquestrar filas de trabalho e um banco de dados gerenciado (PostgreSQL ou MySQL, por exemplo) para armazenamento centralizado das informações e garantir resiliência.
Como funciona a integração do Redis na arquitetura de alta disponibilidade do n8n?
O Redis atua como broker de filas de trabalho, permitindo a comunicação entre os diferentes workers do n8n. Isso possibilita a distribuição eficiente das execuções dos fluxos, evitando gargalos e possibilitando escalabilidade horizontal dos processos.
Quais bancos de dados são recomendados para alta disponibilidade no n8n?
Os bancos gerenciados mais recomendados para alta disponibilidade do n8n são PostgreSQL e MySQL, pois eles garantem replicação, backup automático e failover, proporcionando robustez, disponibilidade contínua e redução no risco de perda de dados.
Conclusão
Configurar o n8n para aguentar produção não precisa ser um salto gigante. O caminho mais sólido — e mais comum — para quem busca como configurar n8n em alta disponibilidade na VPS é separar responsabilidades: usar queue mode com Redis para enfileirar execuções, distribuir carga com workers do n8n em VPS e manter o estado do sistema em um PostgreSQL gerenciado para n8n.
Com esse desenho, você ganha três coisas que mudam o jogo: mais estabilidade em picos, mais paralelismo para processar tarefas pesadas e mais segurança para o “coração” do projeto (o banco). A partir daí, as boas práticas (limites de recursos, monitoramento, backups e atualizações cuidadosas) são o que transformam a arquitetura em disponibilidade real no dia a dia.
Se você montar a base bem feita e evoluir aos poucos (1 worker, depois 2, ajustando conforme a demanda), dá para ter um n8n bem confiável mesmo rodando em VPS — e com espaço para crescer sem precisar reinventar tudo.