Como configurar n8n em VPS com alta disponibilidade: ativa-passiva, replicação do banco e failover
*# Como configurar n8n em VPS com alta disponibilidade: ativa-passiva, replicação do banco e failover
Meta descrição: Aprenda como configurar n8n em VPS com alta disponibilidade com estratégia ativa-passiva, replicação do banco e failover confiável.*
Rodar o n8n em produção é diferente de “só colocar para funcionar”. Quando o n8n vira o coração das suas automações (integrações, webhooks, notificações, rotinas de vendas, atendimento e até agentes de IA), qualquer indisponibilidade vira impacto direto: lead perdido, pedido que não entra, mensagem que não sai, processo que para.
É aí que entra a ideia de alta disponibilidade (HA). Neste guia, você vai entender como configurar n8n em VPS com alta disponibilidade usando uma estratégia ativa-passiva, com replicação do banco PostgreSQL e um failover bem definido. A proposta aqui é ser didático para iniciantes, mas sem esconder as partes importantes.
Antes de tudo, um aviso honesto: HA de verdade não é “mágica”, é processo + arquitetura + disciplina. Se você duplicar servidores sem pensar em dados, sessão, filas e backups, só vai duplicar problemas. O n8n depende muito de:
- um banco confiável (normalmente PostgreSQL);
- persistência de arquivos (por exemplo, para binários e configurações, dependendo do modo de instalação);
- um endpoint estável (domínio, proxy reverso, TLS);
- e, em cenários mais avançados, do modo fila (queue mode) para escalar execução.
Neste artigo, vamos montar o raciocínio completo: por que HA faz sentido (e quando não faz), como planejar a infraestrutura, como funciona a arquitetura ativa-passiva para n8n, e como preparar replicação PostgreSQL + failover automático com testes, monitoramento e segurança.

Se você está no ponto em que o n8n já é crítico para o seu negócio ou para clientes, este é um caminho bem comum e “pé no chão” para reduzir downtime sem entrar imediatamente em Kubernetes.
Por que escolher alta disponibilidade no n8n: benefícios e riscos
Alta disponibilidade no n8n significa reduzir ao máximo o tempo em que sua automação fica fora do ar. Em termos práticos, é você criar uma estrutura para que, se um servidor cair (ou precisar de manutenção), outro assuma rapidamente.
Benefícios reais (onde HA paga o investimento)
Quando o n8n é usado apenas para testes internos, um downtime de 10 minutos não muda muita coisa. Mas quando ele recebe webhooks de produção, dispara campanhas, integra pagamentos ou coordena processos operacionais, HA vira um “seguro” que faz sentido.
Alguns ganhos típicos:
- Menos downtime e menos prejuízo: falhas de VPS, atualizações do sistema e quedas de rede acontecem. A arquitetura ativa-passiva reduz o impacto.
- Manutenção sem pânico: você consegue atualizar o n8n, o sistema operacional ou o proxy reverso no nó passivo, testar e só depois fazer a virada.
- Melhor previsibilidade: com replicação de banco e failover testado, você sai do “rezar para voltar” e entra no “trocar para o nó reserva”.
Riscos e armadilhas comuns (especialmente para iniciantes)
HA tem custo e complexidade. Os erros mais comuns em projetos de failover n8n em VPS são:
1) Achar que “dois n8n” resolvem tudo: se o banco é único (um PostgreSQL sem réplica) você continua com ponto único de falha.
2) Replicar o banco e esquecer o restante: dependendo do seu setup, pode existir necessidade de persistir arquivos (ex.: binários) e manter configurações idênticas (variáveis, encryption key, webhooks URL).
3) Split brain (cérebro dividido): é quando os dois nós acham que são o “ativo” ao mesmo tempo. Para n8n isso pode ser desastroso: duplicação de execuções, webhooks em duplicidade e inconsistência no banco.
4) Failover não testado: a maioria das quedas não acontece em horário bom. Se você nunca simulou o failover, provavelmente ele vai falhar quando você mais precisar.
Quando não vale a pena
Se você está começando e ainda está validando automações, muitas vezes o melhor é:
- um bom VPS único, com backups e monitoramento;
- e um plano de recuperação simples.
Depois que o n8n vira missão crítica, aí sim faz sentido evoluir para estratégia ativa-passiva n8n, com dados replicados e troca controlada.
Se você quer ir além do “rodar n8n” e começar a criar agentes de IA de verdade
Quando você começa a pensar em alta disponibilidade, geralmente é sinal de que o n8n deixou de ser teste e virou peça de produção. Nesse ponto, muita gente também quer dar o próximo passo: criar automações mais inteligentes, com agentes de IA, memória, integrações e projetos prontos para entregar para clientes.
Uma formação que ajuda bastante nisso (principalmente se você é iniciante e quer um caminho guiado) é a Formação Agentes de IA (n8n) da Hora de Codar. Ela é bem mão na massa, com 221+ aulas, 20h+, 21+ projetos e uma base sólida desde instalação/configuração do n8n até agentes com integrações mais avançadas.
Se quiser conhecer a grade e ver se faz sentido para o seu momento, dá para conferir por aqui: https://app.horadecodar.com.br/lp/formacao-agentes-de-ia-n8n?utm_source=blog

Pré-requisitos e planejamento da infraestrutura para n8n em VPS
Antes de configurar qualquer coisa, o que mais reduz dor de cabeça é planejamento. Alta disponibilidade não é só “subir duas VPS”: é garantir que o nó passivo consiga assumir com o mínimo de mudanças e com o máximo de consistência.
O que você precisa decidir (mesmo sendo iniciante)
1) Qual modo do n8n você vai usar
- Modo padrão (single instance): mais simples, mas exige cuidado extra para garantir que só exista um ativo.
- Queue mode (fila): recomendado para alto volume, pois separa “web” de “workers” e permite escalar melhor. Ainda assim, para ativa-passiva você precisa definir o que muda no failover.
2) Banco de dados e consistência
Para HA, o caminho mais comum é PostgreSQL com réplica. Aqui entram conceitos que você vai ver no artigo:
- Primary (primário): recebe escrita.
- Replica (standby): recebe dados via streaming replication.
No n8n, o banco é parte crítica: credenciais, execuções, estados e histórico vivem ali.
3) Identidade e segredos consistentes
É obrigatório que os dois nós do n8n compartilhem as mesmas configurações sensíveis, principalmente:
N8N_ENCRYPTION_KEY(sem isso, ao trocar de nó, você pode perder acesso às credenciais criptografadas);- URL pública correta para webhooks (ex.:
WEBHOOK_URL); - variáveis de banco e de ambiente iguais.
4) DNS, proxy reverso e TLS
O caminho mais simples para “virar a chave” é usar:
- um domínio (ex.:
n8n.seudominio.com), - um proxy reverso (Nginx, Caddy, Traefik),
- e um mecanismo de troca (DNS com TTL baixo, IP flutuante se o provedor oferecer, ou um load balancer com health check).
Tamanho de máquina e rede (sem exagero)
Para começar com HA, dois nós modestos costumam atender, desde que você tenha folga de CPU/RAM e armazenamento rápido (NVMe ajuda muito em banco).
E aqui entra uma dica prática: se você quer rodar n8n em VPS e crescer com tranquilidade, a VPS da Hostinger costuma facilitar bastante, porque você consegue subir o ambiente rapidamente e escalar recursos sem refazer toda a infraestrutura. Além disso, o n8n já pode vir pronto, o que acelera muito a base antes de partir para HA.
Boas práticas que evitam retrabalho
- Tenha um repositório (ou pelo menos um arquivo) com suas variáveis de ambiente.
- Automatize a instalação (Docker Compose ajuda muito) para os dois nós serem idênticos.
- Defina RPO/RTO: quanto de dados você aceita perder (RPO) e quanto tempo você aceita ficar fora (RTO). Isso guia a complexidade do failover.
Esse planejamento é o alicerce para a parte mais importante: entender a arquitetura ativa-passiva aplicada ao n8n.
Vídeo recomendado no YouTube (para complementar a configuração em VPS)
Para reforçar a base de instalação e entender o fluxo completo de colocar o n8n rodando em servidor, este vídeo é um ótimo complemento antes de partir para HA (ativa-passiva, replicação e failover). A ideia é você dominar a instalação “simples” primeiro — e aí evoluir com mais segurança.
Assista aqui: https://www.youtube.com/embed/VCKzXFk_XjM?si=eOBTMrjZNPj3q07Z
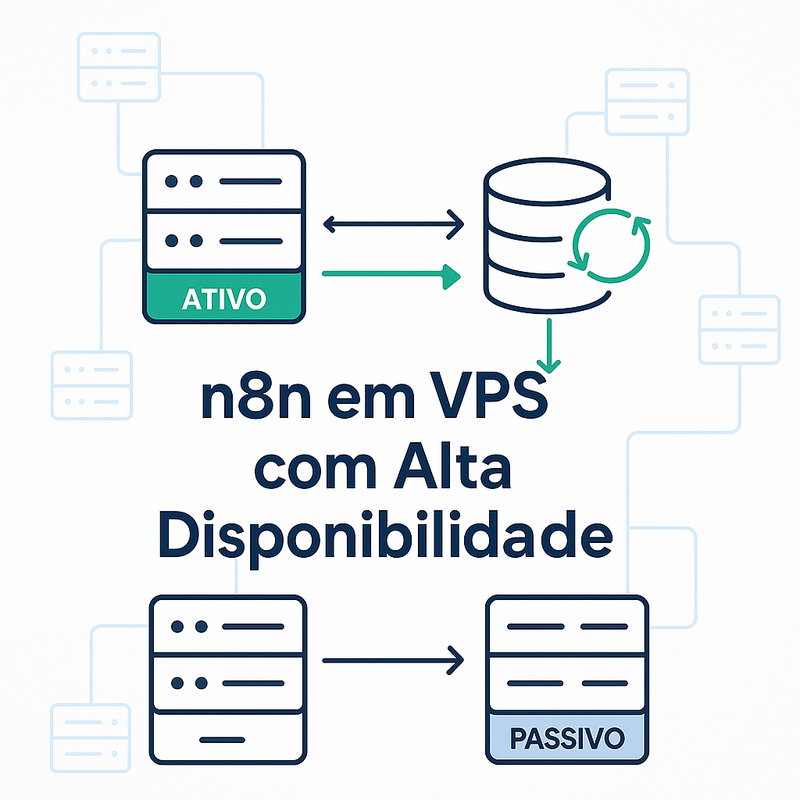
Arquitetura ativa-passiva: como funciona a estratégia para n8n
A estratégia ativa-passiva n8n é uma das formas mais simples de chegar a alta disponibilidade sem cair direto na complexidade de clusters grandes.
O conceito em 1 minuto
- Ativo (active): é o servidor que atende usuários, recebe webhooks e executa fluxos.
- Passivo (passive/standby): fica pronto para assumir, com o mesmo n8n configurado, mas sem estar “valendo” como principal.
A chave é: em um dado momento, só um nó deve estar efetivamente atendendo produção.
O que precisa ser compartilhado e o que pode ser separado
Deve ser consistente/compartilhado (ou replicado)
- Banco PostgreSQL (via replicação): dados do n8n precisam sobreviver ao failover.
- Encryption key do n8n: sem ela, o n8n do nó reserva não consegue ler credenciais.
- Configuração da URL pública: para webhooks e links internos não quebrarem.
Pode ser separado (mas tem que estar igual em comportamento)
- Container/serviço do n8n em cada VPS.
- Proxy reverso local (Nginx/Caddy) em cada nó.
Como acontece o failover na prática
Existem várias maneiras. As mais comuns:
1) Failover manual (mais seguro no início)
Você detecta a falha, promove a réplica do PostgreSQL e aponta o tráfego para o nó passivo. É mais lento, mas reduz risco de “split brain”.
2) Failover automático (mais avançado)
Ferramentas de HA monitoram o primário e, se cair, promovem automaticamente a réplica. Depois, o tráfego muda (DNS, VIP, load balancer). É rápido, mas exige testes.
Onde o pessoal se complica no n8n
O n8n pode receber eventos por webhooks e disparar execuções. Se, durante uma instabilidade, os dois nós atenderem o mesmo webhook, você pode gerar efeitos colaterais:
- duplicar envio de mensagens;
- duplicar criação de registros;
- disparar cobranças em duplicidade.
Por isso, em ativa-passiva, vale ter uma regra clara:
- um único endpoint público (domínio) que aponta para quem está ativo;
- e um mecanismo bem definido de “quem está saudável”.
Quando você entende essa lógica, a replicação PostgreSQL n8n e o failover começam a fazer sentido como parte de um fluxo: detectar falha → garantir dados consistentes → promover banco → subir/ativar n8n no nó reserva → redirecionar tráfego.
Configurando replicação PostgreSQL e failover automático para n8n
Nesta parte, a ideia é te dar um mapa claro do que precisa existir para você dizer: “ok, meu banco aguenta uma queda e eu tenho failover”. Como você pediu foco em iniciantes, vou explicar o caminho recomendado e os pontos de atenção, sem assumir que você já domina administração de PostgreSQL.
Visão geral do setup
Você terá:
- VPS A: n8n ativo + PostgreSQL primário.
- VPS B: n8n passivo + PostgreSQL réplica (standby).
O PostgreSQL vai replicar do primário para a réplica (streaming replication). Quando o primário cair, você promove a réplica para virar primário. A partir daí, o n8n do nó passivo passa a apontar para esse novo primário e assume o tráfego.
Passo 1: preparar PostgreSQL para replicação
No primário, você precisa:
- habilitar parâmetros de replicação (ex.:
wal_level,max_wal_senders,hot_standby); - criar um usuário de replicação com permissão adequada;
- configurar autenticação (no
pg_hba.conf) permitindo a réplica conectar.
Na réplica, você precisa:
- fazer um “base backup” inicial do primário;
- configurar o modo standby apontando para o primário;
- iniciar o serviço e validar que está recebendo WAL.
A validação mais simples é verificar se a réplica está em modo recovery e se o atraso (replication lag) está aceitável.
Passo 2: garantir consistência do n8n nos dois nós
Para o failover do n8n ser confiável:
- use a mesma
N8N_ENCRYPTION_KEYnas duas VPS; - mantenha as mesmas versões do n8n (evita migração de schema em momentos ruins);
- deixe as configs (env vars) alinhadas;
- se você usa armazenamento de arquivos para binários, planeje como persistir isso (ex.: volume compartilhado, sincronização ou estratégia de não depender de binários persistidos).
Passo 3: mecanismo de failover do banco (automático ou semi-automático)
Para failover automático em PostgreSQL, projetos comuns incluem Patroni, repmgr e Keepalived (com scripts) — cada um tem trade-offs. O ponto importante é:
- detectar indisponibilidade do primário;
- promover a réplica com segurança;
- evitar split brain.
Se você está começando, uma abordagem bem sensata é:
- implementar replicação + promoção manual (procedimento documentado);
- depois automatizar quando tiver confiança.
Passo 4: troca do tráfego (n8n ativo)
Você precisa de um “seletor” de tráfego. Opções comuns:
- DNS com TTL baixo (mais simples, mas pode demorar alguns minutos para propagar);
- um load balancer externo com health check;
- IP flutuante/VIP com Keepalived (quando o provedor permite).
O objetivo é: o domínio do n8n sempre apontar para o nó que está ativo.
Um detalhe que muita gente esquece: migrações e manutenção
Evite atualizar o n8n e o PostgreSQL “no susto”. Tenha um fluxo:
- atualize primeiro o nó passivo,
- valide,
- faça failover planejado,
- atualize o antigo ativo.
Isso reduz muito a chance de downtime.
Com isso, você tem a base da replicação PostgreSQL n8n e um caminho realista para failover n8n em VPS. Na próxima seção, vamos fechar com testes, monitoramento e segurança, porque HA sem teste e observabilidade é só teoria.
VPS recomendada para n8n (com espaço para crescer e fazer HA): Hostinger
Para rodar n8n com mais previsibilidade (e depois evoluir para alta disponibilidade), ajuda muito escolher uma VPS que facilite instalação e escala. A VPS da Hostinger costuma ser uma boa opção porque você consegue ajustar recursos conforme o projeto cresce e manter uma infraestrutura estável (eles indicam 99,9% de uptime). E um detalhe prático: os planos contam com n8n pré-instalado, o que economiza tempo na base antes de você partir para réplica, failover e afins.
Você pode ver os planos por este link (com indicação): https://www.hostinger.com.br/horadecodar
E se for contratar, use o cupom HORADECODAR para garantir desconto.
Se você está começando, um plano intermediário (com folga de RAM) costuma evitar gargalos quando as execuções aumentam — e, para HA, você tende a replicar esse padrão em duas VPS (ativa e passiva), já pensando em crescimento.

Checklist de testes, monitoramento e melhores práticas de segurança
Depois de montar a arquitetura, a diferença entre “parece robusto” e “é robusto” está em testar e monitorar. Essa parte é a que mais evita surpresas.
Testes essenciais (simule antes que aconteça de verdade)
O melhor momento para testar failover é quando ninguém depende do sistema.
Você quer conseguir responder:
- Se o PostgreSQL primário cair, em quanto tempo eu promovo a réplica?
- Depois da promoção, o n8n volta a operar com credenciais e webhooks ok?
- O tráfego realmente troca para o nó correto?
Um roteiro prático de simulação:
- Derrube o serviço do PostgreSQL primário (ou desligue a VPS A) e observe.
- Promova a réplica na VPS B.
- Ative o n8n na VPS B (ou promova o tráfego para ele).
- Dispare um webhook de teste e valide se a execução acontece uma única vez.
- Verifique logs e se o histórico de execuções aparece no painel.
Esses testes também ajudam a enxergar dependências invisíveis (por exemplo, um firewall bloqueando porta de replicação, ou o proxy reverso não configurado igual nos dois nós).
Monitoramento: o mínimo que vale ouro
Você precisa monitorar três camadas:
- Infra (VPS): CPU, RAM, disco, rede.
- Banco: replication lag, conexões, espaço em disco, saúde do primário/réplica.
- Aplicação (n8n): endpoint HTTP, filas/execuções, erros e tempo de resposta.
Alertas simples (e úteis) são os que avisam antes da pane:
- disco do PostgreSQL chegando perto do limite;
- aumento de replication lag;
- endpoint do n8n fora do ar.
Segurança: o que não dá para ignorar em produção
Alta disponibilidade não compensa um incidente de segurança. Para n8n em VPS:
- mantenha SSH com chave (sem senha) e, se possível, com portas e regras restritas;
- use TLS/HTTPS sempre;
- limite acesso ao PostgreSQL para rede privada ou IPs específicos;
- guarde variáveis sensíveis em local seguro e evite expor
.env; - faça backups e teste restauração (backup que nunca foi restaurado é “fé”, não plano).
Melhores práticas que simplificam HA
- Padronize: mesmo Docker Compose, mesmas versões, mesmas configs.
- Documente: um passo a passo de “como fazer failover” salva horas.
- Tenha um “modo manutenção” para quando precisar mexer em DNS/infra.
Quando você fecha essa camada, seu projeto deixa de ser “dois servidores” e vira uma estratégia de operação. Isso é o que de fato sustenta como configurar n8n em VPS com alta disponibilidade no dia a dia.
Como funciona a estratégia ativa-passiva de alta disponibilidade para o n8n em VPS?
Na estratégia ativa-passiva, uma instância do n8n fica ativa processando fluxos, enquanto a outra permanece em modo standby. Em caso de falha da instância ativa, o tráfego e processos são redirecionados automaticamente para a instância passiva (failover), minimizando o tempo de inatividade.
Como realizar a replicação do banco de dados do n8n entre as VPSs?
A replicação do banco de dados pode ser feita utilizando bancos como PostgreSQL ou MySQL, configurando o modo de replicação master-slave/primário-secundário. Assim, os dados dos fluxos e execuções do n8n ficam sincronizados entre as VPSs, garantindo a continuidade dos processos após o failover.
Quais são as melhores práticas para implementar failover confiável no n8n em VPS?
Utilize ferramentas de gerenciamento de IP flutuante (como Keepalived ou Heartbeat) para redirecionar automaticamente o tráfego para a VPS ativa em caso de falha. Combine isso com monitoramento constante e o uso de scripts automatizados para promover o banco de dados secundário para primário, garantindo failover rápido e seguro.
Conclusão
Configurar alta disponibilidade no n8n não é só subir duas VPS: envolve desenhar uma arquitetura que evite pontos únicos de falha e, principalmente, que evite comportamentos perigosos como duplicação de execuções. Ao longo do guia, você viu como configurar n8n em VPS com alta disponibilidade usando um caminho bem comum em produção: estratégia ativa-passiva n8n, com replicação PostgreSQL n8n e um plano claro de failover n8n em VPS.
Se você aplicar o básico bem feito — banco replicado, configs idênticas (especialmente encryption key), tráfego com troca controlada, testes de simulação e monitoramento — você já sai do cenário “se cair, parou” para um cenário em que falhas são eventos administráveis.
E vale reforçar: alta disponibilidade é uma jornada. Comece com replicação + failover manual bem documentado, teste algumas vezes, e só então automatize. Esse passo a passo costuma ser o jeito mais seguro (e menos estressante) de chegar em um n8n realmente confiável em produção.
Formações

Formação Vibe Coding
Do Prompt ao Produto: Crie Software Real com IA
- 473 aulas
- 20 projetos
- 39h 26min




Blog | Mais populares

As diferenças de var, let e const

Como fazer redirecionamento com PHP
Neste artigo você vai aprender a como fazer redirecionamento com PHP, utilizaremos abordagens fáceis de entender e de aplicar Fala programador(a), beleza? Bora aprender mais […]

Checklist de segurança n8n VPS pública: guia essencial para proteger sua instalação
Checklist de segurança n8n VPS pública: guia essencial para proteger sua instalação A popularidade da automação de processos com o n8n está em alta, principalmente […]
